Informationstheorie nach Shannon
Die Informationstheorie, die von Claude Shannon in den 40er/50er Jahren entwickelt wurde, stellt ein Maß bzw. Kalkül zur Verfügung den Begriff “Information” und “Informationsgehalt” zu quantisieren um damit rechnen zu können.
Vorbemerkungen
In der Informationstheorie betrachten wir stets Quellen die Zeichen aussenden. Die Menge aller möglichen Zeichen die auftreten können heißt Alphabet und wird in der Regel mit bezeichnet. Ein Beobachter, der die Zeichenquelle betrachtet möchte nun wissen, welche „Information“ in den Zeichen steckt, die die Quelle aussendet.
Um dies zu modellieren bedient man sich der Wahrscheinlichkeitstheorie. Man definiert eine Wahrscheinlichkeitsverteilung auf dem Alphabet. Man weiß dadurch mit welcher Wahrscheinlichkeit welches Zeichen ausgesendet wird. Zum Beispiel sendet eine Quelle die Zeichenkette :
Nachzählen ergibt also, dass wir insgesamt 14 Zeichen bekommen haben und davon 5 Mal die 0 und 9 Mal die 1. Das heißt unsere Wahrscheinlichkeitsverteilung ist
Die Information
Wie bringen wir nun die Information herein? Shannon definierte die Information , die ein Zeichen enthält durch
Die Einheit der Information ist bit. Man beachte, dass dies eine reelle Zahl sein kann (und meistens auch ist), und daher nicht mit dem normal üblichen Bit (Großgeschrieben) zu verwechseln ist!
Es ist also gerade der negative Logarithmus über die relative Auftrittswahrscheinlichkeit des Zeichens ! Das macht auch Sinn, denn der Logarithmus ist zwischen 0 und 1 immer negativ, und eine relative Wahrscheinlichkeit ist stets im Bereich 0 bis 1. Somit ist die Information eines Zeichens stets größer als 0.
Für unser Beispiel ausgerechnet ist demnach
und
Warum ist die Information von 0 höher? Weil sie seltener vorkommt. Wenn die Quelle eine ausspuckt ist das weitaus weniger „überraschend“. Man würde eine also eher erwarten, und erhält damit weniger Information, als wenn eine kommt, da diese verhältnismäßig selten vorkommen.
Durchschnittlicher Informationsgehalt aka „Entropie“
Mit der oberen Formel können wir nun den Informationsgehalt eines Zeichens schön berechnen. Nun möchte man aber vielleicht wissen wieviel Information ein Zeichen in einer Zeichenkette „im Mittel“ enthält. Aus der Wahrscheinlichkeit weiß man, dass dies gerade der Erwartungswert der statistischen Variable – in unserem Fall also – ist. Also
Übertragen wir das auf die Informationstheorie. Wir können für jedes Zeichen ja die Einzelinformationen berechnen. Nun bilden wir einfach den Erwartungswert und das liefert die Formel für die Entropie
Wir können das noch etwas vereinfach, nämlich
Anschaulich ist dies also der durchschnittliche Informationsgehalt eines Zeichens; Und zwar der Zeichen, die die Quelle ausspuckt.
Man notiert auch – analog zur Wahrscheinlichkeitstheorie – die Entropie durch . Wichtig ist dabei, dass die Wahrscheinlichkeiten aufsummiert gerade 1 ergeben, da der Wert sonst illegal ist, bzw. überhaupt keinen Sinn ergibt.
Unser Beispiel von oben mit der Zeichenkette liefert nun eingesetzt in die Formel
Dies ist also die Entropie, also der durchschnittliche Informationsgehalt pro Zeichen der Zeichenkette .
Wollten wir den Informationsgehalt der kompletten Zeichenkette, so müssen wir unser noch mit der Länge der Zeichenkette multiplizieren, also
Die Zeichenkette enthält also eine Information von ungefähr 13 bit!
Der Kanal
Man möchte nun noch einen Schritt weiter gehen und betrachtet nicht nur die Information von Zeichenketten die eine Quelle ausspuckt, sondern man betrachtet einen Übetragungskanal durch den wir einen Datenstrom schicken wollen. Wir brauchen also jetzt zwei Alphabete und , nämlich die des Senders und die des Empfängers.
Nun kann es passieren, dass der Kanal gestört wird, das heißt Informationen des Senders verloren gehen, oder ungewollte Informationen hinzukommen. Die Quelle wird also in der Regel nicht das gleiche Empfangen was der Sender ausgespuckt hat. Schematisch kann man das am folgenden Bild illustrieren:

Keine Panik, das Bild ist schnell erklärt!
Die Quelle (links) sendet Zeichen aus einem Alphabet in den Kanal. Die Quelle empfängt irgendwelche Zeichen aus vom Kanal. Hier muss man jetzt ein wenig aufpassen. Es können in der Praxis und die gleichen Alphabete sein, aber es sind trotzdem verschiedene stochastische Variablen! Der Anteil von Information, der an der Quelle ankommt und tatsächlich vom Sender stammt heißt Transinformation. Der verlorengegangene Anteil an Information von der Quelle heißt auch Äquivokation und der hinzugekommene Anteil heißt Fehlinformation. Man kann sich aus dem Diagramm jetzt wunderbar folgende Beziehungen herleiten:
Transinformation:
Äquivokation:
Fehlinformation (Irrelevanz):
Totalinformation:
Diese Formeln lassen sich natürlich auch (durch ineinander Einsetzen bzw. anderes Ablesen aus dem Diagramm) anders formulieren.
OK, schlagen wir wieder einen Bogen zur Wahrscheinlichkeitstheorie. Man kann und wieder als Zufallsvariablen ansehen. Diese sind in der regel stochastisch Abhängig, außer der Sender hat mit der Quelle nichts am Hut, aber was wär das für ein Kanal? Betrachten wir die Verbundwahrscheinlichkeit stochastisch Abhängiger Größen einmal genauer im Vergleich zu den Informationsgehalten
Diese Beziehung sollte man stets im Kopf behalten. Es gilt: Ein Produkt der Wahrscheinlichkeiten entspricht einer Summation der Entropien, was aus der isomorphen Beziehung zwischen der Multiplikation reeller Zahlen und der Summierung ihrer Logarithmen herrührt.
Nun gibt es noch ein paar Eigenschaften von Kanälen:
Deterministischer Kanal
Ein Kanal heißt deterministisch, wenn für jedes Eingabezeichen klar ist, was deren Ausgabezeichen sein wird. Es muss also gelten , es darf keine Fehlinformation geben!
Verlustfreier Kanal
Ein Kanal heißt verlustfrei, wenn es keine Äquivokation (verlorene Information) gibt, also gilt.
Störungsfreier Kanal
Ein Kanal heißt störungsfrei (oder ungestört), wenn er verlustfrei und deterministisch ist.
Nutzloser Kanal
Ein Kanal heißt nutzlos wenn er keine Information überträgt, bzw. wenn gilt . In diesem Fall sind die Zufallsvariablen für und stochastisch unabhängig.
Schließlich gibt es noch eine Größe, die angibt wieviel Information man maximal durch einen Kanal schicken kann, die sogenannte Kanalkapazität. Diese ist definiert durch
Anschaulich ist dies also unter allen möglichen Wahrscheinlichkeitsverteilungen der Quelle diejenige zugehörige Transinformation, die am größten ist.
Definition von Kanälen
OK, genug der trockenen Theorie. Wie definiert man im Allgemeinen einen Kanal? Eine Möglichkeit ist zum Beispiel durch Angabe der bedingten Wahrscheinlichkeiten . Sowas könnte zum Beispiel für einen Kanal mit und so aussehen:
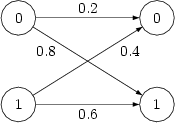
Links haben wir und rechts . Die Pfeile geben die bedingte Wahrscheinlichkeit an. Hat man nun noch eine passende Quellenstatistik gegeben, zum Beispiel
so lassen sich alle Größen des Kanals berechnen. Folgende Größen lassen sich direkt berechnen:
Informationsgehalt der Qelle
Informationsgehalt des Empfängers
Totalinformation
Die restlichen Größen lassen sich mit den Beziehungen aus dem Diagramm leicht herleiten. Für unser Beispiel ergibt sich die Quelleninformation durch:
Die Information lässt sich auch berechnen:
Und schließlich :
Die restlichen Werte lassen sich durch die oberen Formeln ausrechnen, in unserem Fall:
Die Transinformation, also die Information, die der Kanal wirklich überträgt ist mit 0.03 bit in unserem Beispiel leider extrem gering.
Redundanz
Redundanz bezeichnet in der Informationstheorie „überflüssige Information“. Diese kommt dann zustande, wenn man einen Text mit mehr Bits kodiert, als eigentlich nötig, also mehr als die enthaltene Information des Textes.
Definieren wir zunächst einmal die tatsächliche Anzahl bits. Wir haben also wieder ein Alphabet mit Zeichen . Dann bezeichnet das zu gehörende Kodewort. Zum Beispiel beim Alphabet der ASCII-Zeichen hat der Buchstabe das Kodewort , also . Analog zur Entropie , die ein Erwartungswert über die Information der Zeichen ist, ist die Nominalinformation als Erwartungswert über die Kodewortlänge definiert:
Diese ist quasi die „durchschnittliche Kodewortlänge pro Zeichen“.
Wir haben nun also zwei Größen, die wir gegenüberstellen können, nämlich die tatsächliche Kodelänge () und die eigentlich bloß benötigte Kodelänge aufgrund der Information (). Damit ist die absolute Redundanz folgendermaßen definiert
Die relative Redundanz ist dementsprechend ein Wert zwischen 0 und 1 und ist
Ein kleines Beispiel. Betrachten wir die Zeichenkette „Hallo“. Offenbar ist das Alphabet . Die Wahrscheinlichkeitsverteilung ergibt sich durch nachzählen und ist
Damit können wir die Entropie berechnen
Da bei der ASCII-Kodierung jedes Zeichen durch 8 Bit repräsentiert wird, können wir setzen. Somit ergibt sich eine absolute Redundanz von
und eine relative Redundanz von
Um die Information, die die Zeichenkette „Hallo“ enthält zu Kodieren, reichen also 1.92 bit pro Zeichen aus. Im ASCII-Kode sind also pro Zeichen 6.08 bit (76%) „überflüssig“.
Maximale und minimale Information
Sehr interessant ist noch, dass der Informationsgehalt (Entropie) zu einer Zufallsvariable (und einem Alphabet) dann maximal wird, wenn auf dem Alphabet eine Gleichverteilung vorliegt. Intuitiv ist das klar, denn bei einer Gleichverteilung der Zeichen weiß man am wenigsten welches Zeichen als nächstes auftreten wird, daher wird jedes eine hohe Information mitbringen.
Der Informationsgehalt wird im Gegenzug dann minimal, wenn die Wahrscheinlichkeitsverteilung so aussieht, dass ein Zeichen eine Auftrittswahrscheinlichkeit von 100% besitzt. Die restlichen Zeichen haben dann natürlich eine Auftrittswahrscheinlichkeit von 0. Dann bringt ein Auftauchen von nämlich überhaupt keine Information mit, da man ja eh schon wusste dass kommt.